



Robots.txt to niewielki plik tekstowy, który decyduje o tym, co roboty wyszukiwarek mogą przeglądać na Twojej stronie. Mimo prostej składni potrafi narobić sporych szkód — źle skonfigurowany robots.txt zablokuje indeksację całego serwisu albo odwrotnie: wpuści crawlery w sekcje, które powinny pozostać niedostępne. Zrozumienie tego pliku i jego poprawna konfiguracja to jeden z pierwszych kroków optymalizacji technicznej.
Struktura pliku robots.txt i jego dyrektywy
Plik robots.txt znajduje się zawsze w katalogu głównym domeny (np. https://example.pl/robots.txt). Składa się z bloków instrukcji, z których każdy zaczyna się od wskazania agenta użytkownika (User-agent), a następnie zawiera reguły dostępu.
Dyrektywy Disallow, Allow i Sitemap
Dyrektywa User-agent określa, do którego bota odnoszą się kolejne reguły. Gwiazdka (*) oznacza wszystkie roboty, ale można też celować w konkretne — np. User-agent: Googlebot lub User-agent: Bingbot. To pozwala na tworzenie różnych reguł dla różnych wyszukiwarek.
Disallow blokuje dostęp do wskazanej ścieżki. Zapis Disallow: /admin/ oznacza, że roboty nie powinny odwiedzać żadnych podstron zaczynających się od /admin/. Pusta wartość Disallow: (bez ścieżki) oznacza brak blokad — robot może przeglądać wszystko.
Allow działa odwrotnie — zezwala na dostęp do konkretnej ścieżki, nawet jeśli nadrzędny katalog jest zablokowany. Przykład: Disallow: /katalog/ w połączeniu z Allow: /katalog/publiczny/ zablokuje cały katalog poza podkatalogiem publicznym.
Sitemap wskazuje lokalizację mapy witryny XML. Wpis Sitemap: https://example.pl/sitemap.xml pomaga robotom szybciej odnaleźć pełną listę stron do zaindeksowania. Ta dyrektywa nie wymaga wcześniejszego wskazania User-agent — można ją umieścić w dowolnym miejscu pliku.
Najczęstsze błędy w konfiguracji robots.txt?
Błędy w robots.txt potrafią miesiącami sabotować widoczność strony w Google, a ich skutki bywają trudne do zdiagnozowania, bo nie generują widocznych komunikatów o błędach na stronie. Oto sytuacje, które spotykamy najczęściej w audytach technicznych.
Blokowanie plików CSS i JavaScript to jeden z najczęstszych problemów. Google potrzebuje dostępu do tych zasobów, żeby poprawnie renderować stronę i ocenić jej wygląd na urządzeniach mobilnych. Zapis Disallow: /wp-content/themes/ na stronie WordPress skutecznie uniemożliwia Googlebotowi zobaczenie strony tak, jak widzi ją użytkownik — a to negatywnie wpływa na ranking.
- Blokowanie całego serwisu zapisem Disallow: / zamiast Disallow: (pusta wartość). Różnica jednego znaku — ukośnika — decyduje o tym, czy Google widzi Twoją stronę, czy nie. Zdarza się to po migracji, gdy ktoś zapomni zmienić robots.txt z wersji testowej.
- Blokowanie stron, które powinny być w indeksie, np. kategorii produktów, stron filtrowania czy paginacji. Zamiast Disallow lepiej stosować tagi noindex w nagłówkach HTTP — robots.txt blokuje crawlowanie, ale nie gwarantuje usunięcia z indeksu.
- Brak dyrektywy Sitemap — nie jest to błąd krytyczny, ale utrudnia robotom odnalezienie pełnej mapy witryny, zwłaszcza w dużych serwisach z tysiącami podstron.
- Niespójna konfiguracja między wersją z www i bez www — jeśli obie wersje domeny odpowiadają (brak przekierowania), każda potrzebuje własnego robots.txt.
Po każdej zmianie w robots.txt warto zweryfikować plik narzędziem do testowania w Google Search Console. Narzędzie pokaże, czy konkretny URL jest zablokowany czy dostępny dla Googlebota, zanim zmiany wpłyną na indeksację.

Robots.txt w WordPress — gotowa konfiguracja
WordPress domyślnie generuje wirtualny robots.txt, ale nie zapisuje go jako fizycznego pliku. Oznacza to, że plik jest tworzony dynamicznie i można go modyfikować przez wtyczki (np. Yoast SEO lub Rank Math) albo bezpośrednio — tworząc plik robots.txt w katalogu głównym instalacji.
Przykładowa konfiguracja robots.txt dla typowej strony na WordPressie, która sprawdza się w większości przypadków:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-login.php
Disallow: /cart/
Disallow: /checkout/
Disallow: /?s=
Disallow: /search/
Sitemap: https://example.pl/sitemap_index.xmlTa konfiguracja blokuje panel administracyjny (poza plikiem admin-ajax.php, który bywa potrzebny do renderowania), stronę logowania, koszyk, checkout i wyniki wyszukiwania wewnętrznego. Jednocześnie pozwala robotom na swobodne przeglądanie całej reszty serwisu, w tym plików CSS, JS i obrazów.
Jeśli prowadzisz sklep WooCommerce, rozważ dodatkowe blokady dla stron filtrowania z parametrami URL (np. Disallow: /*?orderby=), które generują duplikaty treści. Pamiętaj jednak, że pozycjonowanie stron internetowych wymaga indywidualnego podejścia — konfiguracja, która sprawdza się w jednym sklepie, może blokować istotne podstrony w innym.
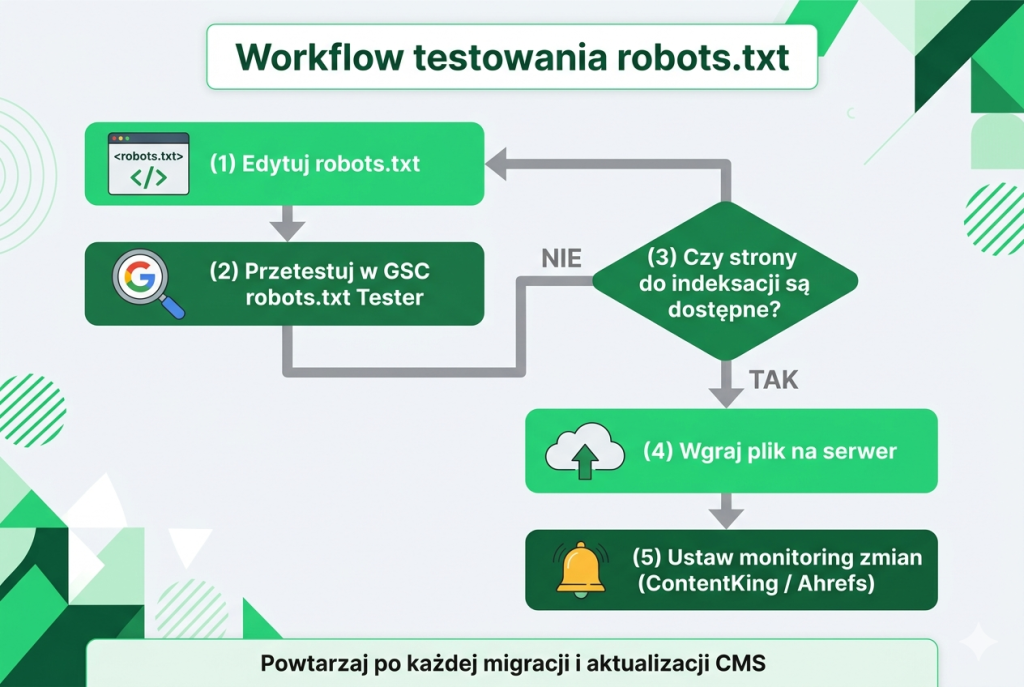
Jak testować i monitorować plik robots.txt?
Samo utworzenie pliku to dopiero początek — robots.txt wymaga regularnej weryfikacji, zwłaszcza po zmianach na stronie, aktualizacjach CMS-a i migracjach.
Narzędzia do testowania robots.txt
Google Search Console oferuje narzędzie „robots.txt Tester” (dostępne w starszej wersji interfejsu), które pozwala wpisać dowolny URL i sprawdzić, czy jest zablokowany czy dostępny. To najpewniejszy sposób weryfikacji — pokazuje, jak Googlebot interpretuje Twój plik.
Screaming Frog i Sitebulb podczas crawlowania serwisu automatycznie raportują URL-e zablokowane przez robots.txt. Jeśli na liście pojawią się strony, które powinny być w indeksie — masz sygnał do poprawy konfiguracji.
Monitoring automatyczny warto ustawić na zmiany w pliku robots.txt. Narzędzia takie jak ContentKing lub Ahrefs Site Audit wysyłają alerty, gdy plik zostanie zmodyfikowany. To zabezpieczenie przed przypadkowym nadpisaniem pliku podczas aktualizacji — sytuacja, którą widzieliśmy dziesiątki razy u klientów zgłaszających „nagły spadek widoczności”.
Robots.txt, a inne metody kontroli indeksacji
Robots.txt nie jest jedynym sposobem zarządzania tym, co trafia do indeksu Google. Warto znać różnice między dostępnymi metodami, bo ich pomylenie prowadzi do nieskutecznych lub sprzecznych instrukcji.
| Metoda | Co robi? | Kiedy stosować? |
| Robots.txt (Disallow) | Blokuje crawlowanie — robot nie odwiedza strony | Strony techniczne, panel admina, duplikaty z parametrami |
| Meta noindex | Strona jest crawlowana, ale nie trafia do indeksu | Strony thin content, tagi, wyniki wyszukiwania |
| X-Robots-Tag (HTTP) | Jak noindex, ale w nagłówku HTTP (dla plików PDF, obrazów) | Pliki niebędące HTML-em |
| Canonical tag | Wskazuje wersję preferowaną przy duplikatach | Paginacja, warianty produktów, parametry filtrowania |
Częsty błąd to łączenie Disallow w robots.txt z noindex na tej samej stronie. Jeśli zablokujesz crawlowanie, Google nigdy nie zobaczy tagu noindex — a strona może pozostać w indeksie na podstawie linków prowadzących do niej z zewnątrz. Jeśli chcesz usunąć stronę z indeksu, nie blokuj jej w robots.txt — pozwól robotowi ją odwiedzić i znaleźć dyrektywę noindex.
Profesjonalna agencja SEO dobiera metodę kontroli indeksacji do konkretnego scenariusza. Robots.txt najlepiej sprawdza się do ochrony zasobów technicznych i ograniczania marnowania budżetu crawlowania na nieistotne URL-e. Do zarządzania tym, co pojawia się w wynikach wyszukiwania, lepiej służą noindex i canonical.






