



Jeszcze kilka lat temu, gdy potrzebowaliśmy odpowiedzi na pytanie, sięgaliśmy niemal automatycznie po Google. Wyszukiwarka stała się naszym codziennym narzędziem – od prostych zapytań po złożone analizy. Dziś jednak krajobraz pozyskiwania informacji wygląda zupełnie inaczej. Na scenę wkroczyły zaawansowane modele językowe, znane jako LLM (Large Language Models), które w ciągu kilku sekund potrafią wygenerować spójną, rozbudowaną i pozornie „ludzką” odpowiedź. Pojawia się więc naturalne pytanie: czy powinniśmy traktować LLM jako konkurencję dla Google, czy raczej jako uzupełnienie jego możliwości?
To porównanie nie jest czysto teoretyczne. Zmienia się bowiem sposób, w jaki konsumujemy treści i weryfikujemy informacje. Jeszcze niedawno proces wyglądał prosto – wyszukiwarka prezentowała nam listę stron, a my decydowaliśmy, w które kliknąć. Teraz coraz częściej dostajemy gotową odpowiedź bez konieczności przeszukiwania setek wyników. Warto więc przyjrzeć się bliżej, jak te dwa światy się przenikają, a gdzie biegną równolegle.
Jak działa Google – ewolucja wyszukiwarki od katalogów stron do sztucznej inteligencji
Google od ponad dwóch dekad pełni rolę głównej bramy do internetu. Od skromnych początków, gdy wyszukiwarka była przede wszystkim narzędziem porządkującym linki w prostych katalogach stron, przeszła długą drogę, stając się zaawansowanym systemem opartym na sztucznej inteligencji. Zrozumienie tej ewolucji pozwala lepiej pojąć, dlaczego Google wciąż dominuje w świecie wyszukiwania i jak jego mechanizmy wpływają na to, jakie treści widzimy w wynikach.
Od prostych algorytmów do PageRank
Na początku Google różniło się od innych wyszukiwarek przede wszystkim algorytmem PageRank. Jego podstawą było analizowanie liczby i jakości linków prowadzących do danej strony – im więcej wartościowych odnośników, tym wyżej dana witryna trafiała w wynikach. Było to rewolucyjne podejście, bo pozwalało ocenić wiarygodność i popularność treści w sposób bardziej obiektywny niż sama analiza słów kluczowych.
Rozwój semantycznego rozumienia treści
Wraz z rozrostem internetu sama analiza linków przestała wystarczać. Google zaczęło wdrażać mechanizmy rozumienia kontekstu zapytań. Wyszukiwarka przestała patrzeć jedynie na pojedyncze słowa, a zaczęła rozpoznawać ich znaczenie w zdaniu. Aktualizacje takie jak Hummingbird, BERT czy MUM zmieniły sposób, w jaki algorytmy interpretują język, co pozwoliło lepiej dopasowywać wyniki do faktycznych intencji użytkownika, a nie tylko do użytych fraz.
Personalizacja wyników i analiza zachowań użytkowników
Kolejnym etapem ewolucji Google stała się personalizacja wyników. Dziś wyszukiwarka nie pokazuje wszystkim tego samego – analizuje naszą historię wyszukiwania, lokalizację, urządzenie, a nawet porę dnia, by dopasować treści do naszych indywidualnych potrzeb. W praktyce oznacza to, że dwa identyczne zapytania wpisane przez różne osoby mogą dać odmienne rezultaty.
Integracja z elementami sztucznej inteligencji
Ostatnie lata to intensywne wdrażanie AI w strukturę wyszukiwarki. Rozpoznawanie obrazów, interpretacja mowy, automatyczne tłumaczenia czy predykcyjne podpowiedzi – wszystko to jest możliwe dzięki zaawansowanym modelom uczenia maszynowego. Google przestało być wyłącznie „mapą internetu”, a stało się inteligentnym asystentem, który potrafi przewidzieć, czego możemy potrzebować jeszcze zanim skończymy wpisywać zapytanie.
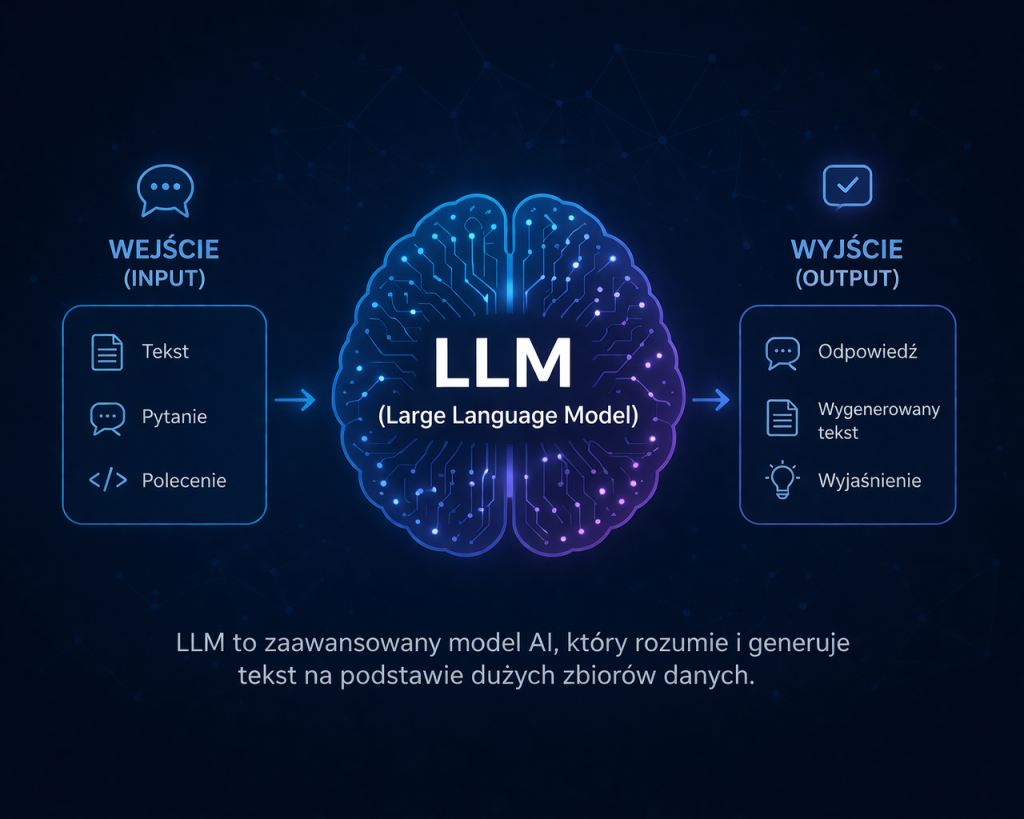
Jak działa LLM – od treningu na gigantycznych zbiorach danych po generowanie odpowiedzi
Modele językowe dużej skali (LLM) to jedne z najbardziej zaawansowanych osiągnięć współczesnej sztucznej inteligencji. Ich działanie opiera się na wieloetapowym procesie, który łączy ogromne zbiory danych, skomplikowane struktury sieci neuronowych i wyrafinowane algorytmy przetwarzania języka naturalnego. Zrozumienie tego mechanizmu pozwala lepiej docenić precyzję, z jaką LLM odpowiadają na pytania i tworzą spójne treści.
Etap treningu – fundament możliwości LLM
Podstawą działania każdego dużego modelu językowego jest proces treningu, czyli uczenia się na podstawie ogromnych zbiorów tekstów. Źródłem danych mogą być książki, artykuły naukowe, strony internetowe, transkrypcje rozmów czy dokumenty techniczne. Istotne jest to, że dane są zróżnicowane, dzięki czemu model uczy się zarówno języka potocznego, jak i terminologii specjalistycznej.
Podczas treningu LLM analizuje miliardy słów i zdań, odkrywając wzorce w ich występowaniu. Algorytm rozpoznaje, jak pewne wyrazy łączą się w kontekście, jak zmienia się znaczenie w zależności od kolejnych fragmentów zdania oraz jakie struktury składniowe dominują w danym języku. Im większy i bardziej zróżnicowany zbiór danych, tym większa precyzja modelu.
Rola architektury sieci neuronowej
Serce LLM stanowi architektura zwana transformatorem (Transformer). To właśnie ona umożliwia modelowi przetwarzanie długich fragmentów tekstu w sposób równoległy, a nie sekwencyjny. Mechanizm tzw. attention pozwala skupić się na tych elementach zdania, które mają największe znaczenie dla kontekstu, dzięki czemu generowane odpowiedzi są spójne i logiczne nawet w skomplikowanych konwersacjach.
Transformatory potrafią analizować jednocześnie wiele zależności w tekście, co daje modelowi zdolność „rozumienia” nie tylko pojedynczych zdań, ale też całych akapitów i powiązań między nimi. To odróżnia LLM od wcześniejszych rozwiązań w przetwarzaniu języka naturalnego, które miały ograniczoną pamięć kontekstu.
Proces fine-tuningu i dostosowania do zadań
Po zakończeniu treningu wstępnego LLM może przejść etap tzw. fine-tuningu, czyli dostrajania do konkretnych zastosowań. Może to być specjalizacja w języku prawniczym, medycznym, technicznym czy marketingowym. Dostosowanie polega na ponownym uczeniu modelu, tym razem na węższym, ale bardziej precyzyjnym zbiorze danych, co zwiększa jego skuteczność w danej dziedzinie.
Generowanie odpowiedzi – krok po kroku
Kiedy wprowadzamy pytanie lub polecenie do LLM, model analizuje je w kontekście wszystkich danych, na których był trenowany. Na podstawie poznanych wzorców przewiduje kolejne słowa, które powinny pojawić się w odpowiedzi. Proces ten nie jest prostym dobieraniem wyrazów – model bierze pod uwagę znaczenie, ton, styl oraz spójność całego tekstu.
LLM ocenia wiele możliwych wariantów odpowiedzi jednocześnie, wybierając tę, która najlepiej pasuje do kontekstu. Dzięki temu jest w stanie tworzyć nie tylko poprawne gramatycznie, ale i logiczne, a często również kreatywne treści.
Podobieństwa w korzystaniu z Google i LLM
Choć Google i modele językowe dużej skali (LLM) to narzędzia o zupełnie odmiennej architekturze i logice działania, z perspektywy użytkownika można dostrzec wiele cech wspólnych w tym, jak z nich korzystamy. Oba rozwiązania opierają się na interakcji tekstowej, dążeniu do szybkiego pozyskania informacji oraz personalizacji wyników, co sprawia, że w codziennym użyciu bywają postrzegane jako alternatywne lub komplementarne źródła wiedzy.
Wspólny punkt startowy – zapytanie użytkownika
Podstawową analogią jest to, że zarówno w Google, jak i w LLM proces pozyskiwania informacji rozpoczynamy od wpisania zapytania w formie tekstowej. W obu przypadkach ważne znaczenie ma sposób sformułowania pytania – im precyzyjniej i bardziej szczegółowo je zadamy, tym większa szansa na otrzymanie odpowiedzi zgodnej z naszymi oczekiwaniami. Zarówno wyszukiwarka, jak i model językowy reagują na kontekst, dobór słów kluczowych i intencję, jaką da się wyczytać z treści zapytania.
Szybkość dostarczania informacji
Google od lat słynie z błyskawicznego wyświetlania wyników wyszukiwania, a LLM w równie imponującym tempie generuje odpowiedzi. W obu przypadkach użytkownik zyskuje dostęp do treści w czasie rzeczywistym, bez konieczności długiego oczekiwania. Ta natychmiastowość reakcji jest jednym z powodów, dla których obie technologie stały się nieodłącznym elementem codziennej pracy i nauki.
Możliwość personalizacji wyników
Zarówno Google, jak i LLM potrafią dostosować odpowiedzi do kontekstu użytkownika. W przypadku wyszukiwarki personalizacja opiera się na historii wyszukiwań, lokalizacji czy preferencjach językowych, natomiast LLM korzysta z kontekstu rozmowy oraz stylu wcześniejszych interakcji. W obu przypadkach efekt jest podobny – użytkownik otrzymuje treści dopasowane do swoich potrzeb, co zwiększa trafność i użyteczność odpowiedzi.
Interakcja oparta na języku naturalnym
Kolejnym podobieństwem jest możliwość komunikowania się w sposób zbliżony do rozmowy z drugim człowiekiem. Google od lat rozwija wyszukiwanie głosowe i obsługę zapytań w języku naturalnym, a LLM są wręcz zaprojektowane do takiej formy interakcji. Dzięki temu użytkownicy mogą zadawać pytania w potocznej formie, bez konieczności stosowania sztywnych formuł wyszukiwania.
Wspólny cel – szybkie znalezienie rozwiązania
Niezależnie od technologii, zarówno Google, jak i LLM pełnią podobną funkcję – mają pomóc w znalezieniu odpowiedzi, rozwiązania problemu lub inspiracji do działania. Choć mechanizmy stojące za ich pracą są odmienne, efekt końcowy z punktu widzenia użytkownika może być bardzo podobny: szybkie uzyskanie wartościowej informacji, która pozwoli podjąć dalsze decyzje lub wykonać konkretne zadanie.
Ewolucja sposobu korzystania z informacji
W miarę rozwoju obu narzędzi można zauważyć, że Google i LLM coraz bardziej zbliżają się do siebie pod względem doświadczenia użytkownika. Wyszukiwarka coraz częściej prezentuje gotowe odpowiedzi w tzw. featured snippets, a modele językowe wzbogacają swoje wypowiedzi o odwołania do źródeł. Ostatecznie w obu przypadkach użytkownik dąży do tego samego – możliwie najmniejszym wysiłkiem uzyskać możliwie najlepszą odpowiedź.
Najważniejsze różnice w funkcjonowaniu Google i LLM
Choć zarówno Google, jak i modele językowe dużej skali (LLM) służą nam do pozyskiwania informacji, ich sposób działania, źródła danych i logika generowania odpowiedzi znacząco się różnią. Zrozumienie tych różnic pozwala świadomie korzystać z obu narzędzi, wybierając to, które najlepiej odpowiada na nasze aktualne potrzeby.
Różnice w źródłach danych
Google działa w oparciu o indeksowanie treści dostępnych w internecie. Algorytmy wyszukiwarki stale analizują miliardy stron, katalogują je, a następnie sortują wyniki według setek czynników rankingowych. Odpowiedzi, które widzimy w wynikach wyszukiwania, są więc wprost powiązane z istniejącymi, aktualnymi dokumentami.
Z kolei LLM generuje odpowiedzi w oparciu o wzorce wyuczone na ogromnych zbiorach danych zgromadzonych w procesie treningu. Nie przeszukuje internetu w czasie rzeczywistym, lecz tworzy treść na podstawie zinternalizowanej wiedzy i statystycznych zależności między słowami.
Różnice w sposobie prezentacji odpowiedzi
Google zazwyczaj dostarcza listę linków do źródeł, z których możemy samodzielnie czerpać informacje. Nierzadko pojawiają się także tzw. featured snippets lub panele wiedzy, ale główną formą są odesłania do stron zewnętrznych.
LLM natomiast podaje gotową, spójną odpowiedź w formie pełnego tekstu, często z możliwością dalszego doprecyzowania poprzez kolejne pytania. W efekcie oszczędzamy czas, ale tracimy bezpośredni kontakt z oryginalnymi źródłami, o ile model ich sam nie wskaże.
Aktualność informacji
Wyszukiwarka Google korzysta z indeksu stale aktualizowanego – treści dodane w sieci mogą pojawić się w wynikach nawet w ciągu kilku minut. Dzięki temu mamy dostęp do najświeższych wiadomości, raportów i analiz.
LLM bazuje na danych z momentu zakończenia swojego treningu, dlatego jego wiedza może być nieaktualna w przypadku wydarzeń bieżących czy dynamicznie zmieniających się branż.
Mechanizm interpretacji zapytań
Google interpretuje zapytanie, dopasowując je do istniejących dokumentów, a jego skuteczność opiera się na trafnym dopasowaniu słów kluczowych, synonimów oraz intencji użytkownika.
LLM rozumie zapytanie kontekstowo – analizuje znaczenie zdań w sposób podobny do ludzkiego przetwarzania języka, a następnie tworzy odpowiedź od zera, uwzględniając ton, styl i logikę całej rozmowy.
Weryfikacja i wiarygodność treści
Google daje możliwość samodzielnej weryfikacji informacji poprzez odwiedzenie źródła. Mamy pełną kontrolę nad tym, jakie treści uznajemy za rzetelne.
W przypadku LLM odpowiedzi są syntetyczne i oparte na jego „wewnętrznej wiedzy”, co oznacza, że użytkownik powinien zachować krytyczne podejście i – w miarę możliwości – potwierdzać istotne informacje w zewnętrznych źródłach.






